

La paranoia de algunos Webmasters no tiene límites, durante algún tiempo se comenzó a hablar sobre Crawl Budget o Presupuesto de rastreo, como si fuese extremadamente importante para el SEO.
Se han planteado un montón de explicaciones estrafalarias e insólitas, hasta alguien ha asegurado en algún blog, que será un factor importante para el SEO en un futuro.
Muchachos, paren la pelota que en este partido no jugamos….
El presupuesto de rastreo no es nuevo, existe en Google desde que nació el buscador a finales de los 90, ¿Qué pasó que 20 años más tarde de pronto cobra tanta importancia?.
Absolutamente nada, sólo que algunos recién ahora lo han descubierto.
Esta ola de rumores hizo que Google tuviera que salir a aclarar sobre el tema en una nota del Blog oficial para Webmasters
Allí explica que, en condiciones normales, crawl budget no debería ser un problema para la mayoría de los sitios web, pero para entenderlo mejor vale la pena tener una noción básica sobre cómo se comportan los robots de Google cuando exploran un sitio web
Googlebot se trata en realidad de 2 tipos de robot:
Freshbot: Es un robot de rastreo superficial, se encarga de rastrear todas las páginas del sitio web en busca de nuevos contenidos, y su tarea se ve facilitada si existe un sitemap.
DeepBot: Robot de rastreo profundo, de él depende la indexación y el análisis cualitativo de las nuevas URL que encuentra FreshBot.
Ambos están limitados a una frecuencia de rastreo, y ésta a su vez, está limitada por la carga máxima del host, que es la capacidad del servidor soportar múltiples peticiones simultáneas.
Crawl Budget es precisamente el encargado de fijar esos límites, y administrar el rastreo para evitar sobrecargar al servidor.
Si googlebot detecta que el servidor no está respondiendo correctamente, baja la frecuencia de rastreo y explora solamente las páginas más visitadas y relevantes del sitio en cuestión.
Para una web con muchos miles de URLs, implica que un gran porcentaje de ellas no serán rastreadas, y aunque Google sostenga que no es un factor determinante para la clasificación, después de un tiempo puede perjudicar el volumen de tráfico, al degradar en los resultados las páginas afectadas
¿Cómo determina Google cuáles serán las URL que debe rastrear en esa situación?
Como ya sabes, el algoritmo utiliza múltiples factores para determinar la importancia de una página, pero en una situación de contingencia con limitaciones del servidor, puedes intentar indicarle a Google cuales son las URL que debería rastrear.
Usualmente, se incluyen en uno o varios sitemps, todas las URL del sitio. En este caso, la idea es utilizar un sitemap personalizado, sólo con las páginas más relevantes. Eso implica remplazar temporalmente, el o los sitemaps que estaban en uso
Otro factor que determina cuáles serán esas páginas, es su PageRank… Si, el mismo!!.. aunque no lo veas, siempre está activo (Gary Illyes dixit)
— Gary Illyes ?( ? )? (@methode) 2 de agosto de 2016
Pero recuerda que es una situación de contingencia, mantener un sitio web en esa situación puede tener consecuencias impredecibles para el SEO, la solución es cambiar de servidor o aumentar su capacidad y ancho de banda.
¿Como saber si tu servidor te está quedando chico?
Los primeros indicios los tienes en la métricas de Search console, puntualmente en Indexación de páginas (cobertura de rastreo), hay un incremento en la cantidad en Descubierta: actualmente sin indexar.
Para verificarlo puedes acceder al Informe “Estadísticas de rastreo”. Allí verás una curva con el registro diario de páginas rastreadas en los últimos 90 días.
Si tienes una actividad regular y conocida en el sitio, por ejemplo, si tu web es un blog donde publicas una página por día y crecen paulatinamente las visitas, notarás el incremento paulatino de las páginas rastreadas, y si tienes éxito, la cifra indicada como valor Normal, será superior a la cantidad de páginas publicadas
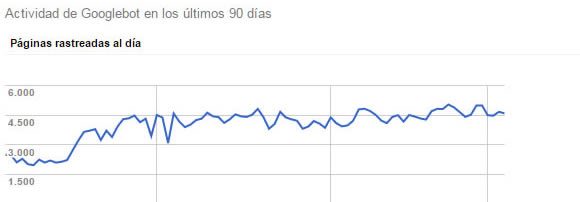
Si por el contrario, no hay incremento en la curva sino que baja o se mantiene sin cambios, es posible que googlebot haya bajado drásticamente la frecuencia de rastreo, porque el servidor no tiene recursos suficientes. Puedes comprobar si hay errores del servidor en Search console y examinar el reporte de errores en el panel de control del propio servidor.
Qué hacer si el problema no está en el servidor?
Si sabes positívamente que el comportamiento del servidor es satisfactorio, y no has introducido cambios, es evidente que hay algo en el diseño de tu sitio que está dificultando el rastreo por diferentes motivo:
- Sitio infectado o pirateado: En estos casos hay un código malicioso que genera infinidad de páginas spam que aumenta el presupuesto de rastreo
- Páginas de baja calidad o duplicadas: La indexación de resultados de consultas internas, por ejemplo, puede elevar los duplicados al infinito y agotar hasta el servidor mas potente
- Excesiva cantidad de páginas o recursos bloqueados: A pesar de lo que supones, las URL bloqueadas por robots, son rastreadas de todos modos.
- Cambio de diseño: Si has elegido una plantilla que genera páginas muy voluminosas en html, estas requieren mas conexiones simultáneas para el rastreo, ralentizando el proceso.
Antes que se te ocurra, no ajustes la frecuencia de rastreo preferida desde Configuración del sitio en Search console, es posible que empeores la situación. Esa herramienta solo se utiliza en determinadas ocasiones, para bajar la frecuencia y no al revés.
Conclusión
Como has visto, el presupuesto de rastreo, no ayuda a posicionar tu sitio web, pero te asegura que Google siempre pueda rastrearlo, solo debes asegurarte que se mantenga accesible y que esté alojado en un servidor acorde a las necesidades. Si lo has logrado, olvídate del bendito Crawl Budget, por favor.