
 Hace tiempo que el motor de búsqueda de Google ha cambiado el modo de tratar las URLs bloqueadas para googlebot, y esto confunde un poco a los webmasters desprevenidos:
Hace tiempo que el motor de búsqueda de Google ha cambiado el modo de tratar las URLs bloqueadas para googlebot, y esto confunde un poco a los webmasters desprevenidos:
Normalmente si esto sucedía, la página bloqueada dejaba de aparecer en los resultados en cuanto se actualizara el indice del buscador.
Pero eso ya no es así, Google muestra de todos modos las página bloqueadas, pero con la siguiente leyenda en el lugar de la descripción:
No hay información disponible sobre esta página.
Sin embargo el titulo y su contenido aun siguen indexados, como en este ejemplo:
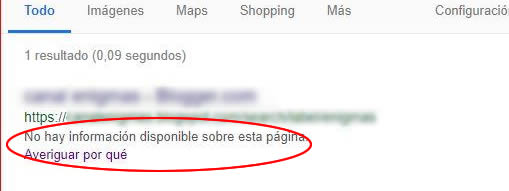
Supongamos que tienes páginas con contenido duplicado, lo primero que se nos ocurre es bloquear una de ellas a los robots, pero como vemos en el ejemplo, aun son accesibles para una consulta de búsqueda determinada, de tal modo que el contenido duplicado seguirá estando presente.
En este punto si estabas confundido, ahora seguramente estás completamente desconcertado:
– Si usé correctamente el archivo robots, ¿por que aparecen esas páginas si están bloqueadas?-
Exceptuando el caso que se da cuando googlebot ha indexado la URL sin restricciones, y posteriormente se la bloquea. El hecho es que Google puede rastrear una URL, cuando se encuentra bloqueada por el archivo robots.txt
Lo que está sucediendo, es que la orden de bloqueo evita que los robots indexen una pagina, pero no evita que la sigan rastreando. Si el algoritmo considera que esa página es la mas adecuada a una consulta de búsqueda, la muestra en los resultados de todos modos, pero indicando la advertencia de bloqueo.
¿Como evitar entonces que aparezcan esas páginas en los resultados?
Debes recurrir a Google Search Console >> Indice >> Retirada de URLs e ingresar una a una las páginas que se desean ocultar en el indice.
Luego de que se actualice la caché del buscador (24 a 48 Hs.), las URL desaparecerán de los resultados durante 90 días, luego de ese plazo Google volverá a intentar indexarlas, pero debes utilizar la meta etiqueta robots en las páginas que has ocultado, para que no las pueda volver a rastrear ni tampoco indexar.
<meta name="robots" content=”noindex, nofollow”>
Allí esta la diferencia, se puede decir que el archivo robots, puede evitar la indexación pero no el rastreo, en cambio la meta etiqueta robots bloquea ambos; rastreo e indexado.
Google puede rastrear una URL aun si esta se encuentra bloqueada por el archivo robots.txt #SEO #Robots Compartir en X
Hola Carlos,
No puedo encontrar el error que causa que, al buscar mi sitio la página principal tenga el error: No se dispone de una descripción de este resultado debido a robots.txt. Más información.
El contenido del meta de robots del index es:
El contenido de robots.txt:
User-agent: *
Allow: /cursos-rosario/
Disallow: /cgi-bin/
Disallow: /_images/
Disallow: /com/
Disallow: /Scripts/
Disallow: /SpryAssets/
Disallow: /cursos/
Disallow: /admin/
Disallow: /Connections/
Disallow: /css/
Disallow: /cuadrantes/
Disallow: /include/
Disallow: /javascript/
Disallow: /mailings/
Disallow: /media/
Disallow: /Templates/
Entiendo que no deberia haber problemas con index, pero no se porque no lo esta tomando…
Gracias!
Esteban
Hola Esteban
Tal vez te sirva esta referencia:
302 – Moved Temporarily (http://www.onoffsolutions.com.ar/) ?
404 – Not Found (http://include/mobilDetect_JS.php)
Por alguna razón hay una dirección temporal al la detección de móviles que no se encuentra.
Para mas informacion consulta en el foro para webmasters:
https://productforums.google.com/forum/?hl=es#!forum/webmaster-es
Excelente Carlos! Te agradezco muchísimo la velocidad en la respuesta. Esto me da una pista por donde puede estar viniendo el error, así que me voy a poner a investigar.
Saludos!
No doy respuestas sobre Adsense por este medio, pero como bien te recomienda Caro, visita el foro de Google donde seguramente te podrán asesorar mejor.
O bien envíame un mensaje por el formulario de contacto y te haré un presupuesto por mi asesoría.
Salu2
Hola carlos, me puedes ayudar con el mensaje por favor, disculpa es que muy sonfuso lo que adsense dice…
Lee detenidamente las TOC de Adsense http://goo.gl/Ci5yP
O consulta directamente en foro oficial de Google Adsense http://goo.gl/PnYsx
Holal Carlos, me puedes ayudar con este mensaje de adsense que puede ser el problema en el blog?
Explicación de la infracción
Los sitios de publicación de AdSense deben ofrecer un valor significativo al usuario a través de contenido exclusivo y relevante. Los anuncios no deben publicarse en páginas generadas automáticamente o con poco o nada de contenido original.
El sitio debe estar bien estructurado y ofrecer una navegación fácil con el fin de proporcionar una buena experiencia de usuario. Los usuarios deberían poder acceder fácilmente a las páginas de su sitio y encontrar la información que buscan.
Gracias…
Te recomendaría acudir como te lo ha mencionado Carlos, al Foro para Webmasters de Google, por lo que se puede ver, lo que sigue no solo es el cobro por la asesoría de Carlos (página empresarial) sino posiblemente la extinción inminente del sitio en Google.
Hola Carlos, gracias por tu respuesta, ok esto es lo que entiendo: se bloquean los tags,paginaciones y categorias a los rastreadores hasta aqui bien entiendo.
Pero los anteriores quedan indexados en el buscador de google?
Y porque all one in seo pack recomienda poner los tags?
Gracias Carlos, por tus ayudas…
Hola Carlos, me ayudo mucho el enlace, pero entiendo que la Keywords google no las toma en cuenta, pero los tags es muy diferente o me equiboco? gracias
Los tags, al igual que las categorias y paginaciones, son contenido duplicado y deben bloquearse el acceso a los rastreadores.
Salu2
Lee este enlace http://goo.gl/UkRb3
Hola, Carlos disculpa tantas preguntas es que estoy aendiendo de muchos errores, bueno mi pregunta es como es la mejor forma de poner lo tags en el plugin All in one seo pack?
Explico: titulo del articulo(compro carros usados y nuevos)
1- tag (carro,automovil,coche,)
2- tag (carros usados,carros nuevos,compro carros,)
Cual es la mejor manera en poner los tags en la forma 1 o la forma 2, en palabra o una frase corta? gracias
ok, Gracias Carlos
Hola Carlos, Gracias por tu ayuda…
Me puedes ayudar en este problema, me salio este mensaje en dos sitios webs no se si fue despues que instale el robots.txt de tu sitio o es casualidad, este es el mensaje:
Google no ha podido acceder a tu sitio debido a una incidencia relacionada con la conectividad del servidor.
hable con la empresa de hosting que tengo y dicen que ellos revisaron y que todo esta bien.
He leido que hacer pero no tengo claridad como resolver este problema, me puedes ayudar gracias…
El servidor no estaba en linea ocasionalmente cuando el robot intentó rastrear el sitio.
Consulta mas opiniones en el Foro para webmasters de Google
Salu2
Hola carlos, este es el que me sale
User-agent: *
Disallow: /wordpress/wp-admin/
Disallow: /wordpress/wp-includes/
ESTA BIEN?
Te lo repito nuevamente, copia el robots.txt te mi sitio.
Salu2
Copia el robots.txt te este sitio
Salu2
Hola, carlos el robot.txt esta bien o que me recomiendas ponerle ..gracias por tu tiempo
Hola Carlos, gracias porcontestar.A este robots.txt esta bien o que faltariapara las recomendacones que me dices.. gracias
User-agent: Mediapartners-Google
Disallow:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /*/trackback/
Disallow: /category/
Disallow: /cgi-bin/
Disallow: /*/feed/
Disallow: /*.php$
Disallow: /page/
Disallow: /*?
Lo mejor que puedes hacer es evitar que se indexen contenidos irrelevantes, duplicados y de mala calidad, ejemplo: tags, categorias, paginaciones y resultados de búsqueda interna (/search/).
En una palabra, solo los artículos y las páginas estáticas.
Salu2
Hola, carlos que me recomiendas en mi ssitio elcartel ? gracis por tu tiempo
1 – si tienes razon,lo que paso es que puse muchos tags en los articulo en el plugin all one seo pack y por eso creo que fue el problema..que me recomiendas para este sitio elcartel.info? por que el page rank esta en cero. como puedo organizar ese sitio para mejorarlo?..gracias.
2 – Me puedes ayudar como es la mejor optimizacion del plugin All one seo en los tags, ejemplo titulo de articulo( se venden carros usados y nuevos en buen precio) se escribe una palabra espesifica en el tag como (carros,automoviles,vehiculos) o una frase corta (carros usados,donde cmprar carros,venta de carros, y cuantos tags mas o menos por articulo..
saludos..
Hola Juan
Tu primer sitio (elcartel) tiene 64.700 paginas indexadas de las cuales un alto porcentaje son duplicadas (imposible publicar esa cantidad de notas en 2 años).
De tal modo que 7.321 paginas bloqueadas es muy poco.
Tu segundo sitio (colombianostv), tiene un problema aleatorio de conectividad en el servidor, consulta con el administrador del mismo.
Salu2
Hola carlos, me llego este mesaje en mi sitio que dice esto:
http://colombianostv.com/: el robot de Google no puede acceder a tu sitio19 de abril de 2013
Durante las últimas 24 horas, el robot de Google ha encontrado 87 errores al intentar recuperar la información de DNS de tu sitio. La tasa de error general de las consultas DNS del sitio es de 4.3%.
Errores del sitio Mostrando datos de los últimos 90 días
DNS – Conectividad del servidor – Información de robots.txt
Google no ha podido acceder a tu sitio debido a una Error de DNS
icocnorojo= Inaccesible
icono amarillo= Tiempo de espera agotado
icocno azul= Total de errores de DNS
nose que pudo pasar no he tocado nada, que puedo hacer?
Hola Carlos, necesito ayuda veo que aparece esto en URL bloqueadas:
Archivo robots.txt URL bloqueadas Descargado Estado
http://elcartel.info/robots.txt 7.321 19/04/2013 200 (Correcto)
este mi robots.txt:
User-agent: Mediapartners-Google
Disallow:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /*/trackback/
Disallow: /category/
Disallow: /cgi-bin/
Disallow: /*/feed/
Disallow: /*.php$
Disallow: /page/
Disallow: /*?
Sitemap: http://elcartel.info/sitemap.xml
Mi sitio esta con wordpress, por que aparecen 7.321 urls bloqueadas?
Carlos, eres GENIAL.
Por arte de magia, después de un mes, ya aparezco en google por las entradas, muchas gracias, de verdad, ha sido Automático.
Y para abusar un poco más…, mirando en site:mi sitio… aparece el nombre de las entradas, pero en búsquedas lo que aparece es el nombre
“Calzados Lucía”, no el título de la entrada, aunque la descripción sí la pone, que aunque no queda mal, la foto en la búsqueda al pasar el ratón, no es la que le pertenece, debo poner otro meta-etiquetas…
Muchísimas gracias, Carlos
Está correcto, Juani.
Si aparece en los resultados del buscador, no quites ni agregues nada.
Salu2
Juani, el sitio aparece indexado con 49 resultados: http://goo.gl/2oksX.
El hecho que no aparezca en las busquedas con los terminos acostumbrados puede deberse a varios factores, por ejemplo:
En la barra lateral, en el apartado “¿Qué buscas?”, hay mas de 300 palabras que pueden considerarse keyword stuffing, e intento de manipulacion de resultados.
Quita todas esas palabras y solicita un reconsideración.
Salu2
De acuerdo, ahora mismo le mando un e-mail, pero tendrías idea de por qué no aparecen mis entradas en google?, acaso me podrian haber penalizado por convertir un blog en exposición de una tienda?
ya que no aparezco en búsquedas de claves ni en la página 40, y eso que en el primer mes estaba todos mis artículos, y me aparecían visitas con palabras claves, ahora ni una así.
Muchísimas gracias.
Hola Carlos, a mí también me pasa eso cuando pongo site:misitio, el robot me bloquea páginas, pero se lo dije a mi informático y me ha dejado el robot sin bloquear search, así:
User-agent: *
Allow: /
Mapa del sitio: http://calzadoslucia.blogspot.com/atom.xml?redirect=false&start-index=1&max-results=500
¿qué puedo hacer, lo dejo como antes?
ya que si tengo duplicaciones o cómo las puedo quitar. El problema es que cuando creé el blog en noviembre empecé a salir en todas la entradas y de repente hace un mes dejé de aparecer y no sé a qué es debido, en herramientas de w. me pone que tengo bloqueadas 182 e indexadas 124.
Muchas gracias
Hola Juani, Muy mal hecho, JAMAS hay que alterar el contenido de robots.txt en Blogger, ya que este se encarga de bloquear el contenido duplicado de la carpeta /search/.
Si en las herramientas para webmasters aparecen bloqueos, la mayoria de las veces se trata de esa carpeta, ya que su contenido no se debe indexar
Dile a tu informático que vuelva colocar el archivo como estaba.
Salu2
Carlos Muy buen dia
Estoy tratando de entrar en la pagina de herraminets de palabars clave de google y me sale:
Herramienta de palabras clave – Google AdWords adwords.google.es/o/Targeting/Explorer?__u…c…IDEAS
No se dispone de una descripción de este resultado debido a robots.txt. Más información.
No se que hacer para poder accesar a esa pagina, que pueo hacer al respecto. te agradzco mucho el apoyo y la ayuda.
Gracias,
Carlos Ortiz
Hola Carlos
Si entiendo bien, el texto
No se dispone de una descripción de este resultado debido a robots.txt. Más información.pertenece a los resultados del navegador cuando una página está bloqueada y no cuando tratas de acceder a esa herremienta.A proposito, este es el enlace correcto: Herramienta para palabras clave
Salu2
Hola Carlos , a mi me pasa como a Ana , yo no he bloqueado nada , en cambio los robots me han bloquedo 295 paginas y hay 57 de no seleccionadas. He buscado lo que le has dicho a Ana pero no lo encuentro.
Ya no se que hacer me han bajado las visitas ( no se si es debido a que me cambié la plantilla , tenia una dinámica y ahora es simple ).
En herramientas para webmasters no la cambiarón y yo añadi el sitio con la plantilla nueva que se acaba con com.es la de la plantilla dinámica se acaba en com. ) Tiene algo que ver? quito alguna cosa?
Gracias por ayudarme , y es que no se que hacer , ya no entiendo nada.
Un saludo
Montse
Hola Montse
No te preocupes, Blogger bloquea naturalmente la carpeta /search/ de tu blog porque allí se alojan los resultados de búsqueda interna, que no son mas que contenido duplicado. Es una suerte que así sea, si esas 295 páginas no se hubiesen bloqueado, tu blog hubiese sido penalizado por contenido duplicado.
Salu2
Arturo, si es un blog de Blogger, deberias ver el estado del archivo robots.txt y los encabezados en “Configuracion” >> “Preferencias de busqueda”, para mas datos busca en el Foro de Blogger http://goo.gl/LFaFH
Gracias, Gabriela G. ¿y como puedo solucionarlo?
Hola Arturo, eso indica que tu blog no está en el indice de Google.
Creo que el problema está en el archivo robots.txt que esta impidiendo que Google pueda rastrearlo.
Cuando pongo site:mi blog. Me pone “no obtuvo ningún resultado”
Cuando me voy a Estado de indexación me sale que tengo 5 Páginas bloqueadas por robots ¿qué tengo que hacer? ¿como puedo saber que pagina tengo bloqueda?
Hola Arturo
Puedes ver el estado del archivo robots.txt en URL bloqueadas de la Herramientas para webmasters.
Además puedes buscar el estado de tu sitio usando el comando site:, por ejemplo; site:www.tusitio.com y en el final del listado pulsar en repetir la “búsqueda incluyendo los resultados omitidos“.
Veras de ese modo las URLs cuya descripcion muestre “No se dispone de una descripción de este resultado debido a robots.txt.“
Hola Gabriela
La respuesta es sencilla: el sitio está bloqueado a los buscadores por el archivo robots.txt, presente en el directorio raíz del servidor.
O lo quitas o lo editas para que deje de bloquear el acceso.
Lee mas acerca de este archivo en: http://www.robotstxt.org/robotstxt.html
Salu2
Hola Carlos
encantada de la virtualidad..! te encontrè navegando, tuve muchos problemas con mi sevidor que me bloqueo sin comunicaciòn mi pagina por espacio por muchos anos sin darme respuesta concreta, en fin paso todo..!| y bueno no quisè màs esperar el lento de trabajos que me realizaba uno de mis webmaster y sin ningun problema decidi realizar por mi misma mi pagina web dandole una originalidad simple ( para mi) o cambiando deves en cuando los stilos, en fin una aventura pero tengo un problema ultimamente una pagina url externa que uso para news y mostrar mis esculturas no se ven màs en el buscador cosa que no pasaba, francamente me parece extrano, podrìas explicarme por favor que es lo que pasa y que tengo que hacer para asegurar que nadie ingrese a mis paginas o dominio sino la titular, porque deseo fervientemente construirla sola y manejarla sola, es un deseo como mi mismo trabajo me encanta realizar mis cosas por mi misma y mi manera, necesito tu ayuda un gracias sincero por tu ayuda.
perdona no me gusta ser victima de mi ignorancia por eso suelo experimentar metiendo en competencia mi misma capacidad…!
Hola Carlos! Yo no he bloqueado ninguna URL en mi web, pero el mensaje que me aparece en google es “No se dispone de una descripción de este resultado debido a robots.txt” ¿Qué puedo hacer para solucionarlo? Saludos y gracias!
Hola Ana
En algún lado debe estar el bloqueo, si no es en robots.txt será en la metaetiqueta:
“meta name=”robots” content=”noindex, nofollow”
Si no la encuentras me avisas.
Salu2
La actualización de datos en Webmasters Tools no es instantanea, a veces suele tardar mas de una semana en actualizar, paciencia.
Salu2
Ok. Ya lo he hecho, incluso ya me sale eliminado. Pero en mejoras HTML (que me sale una fecha de actualizado del día de hoy) que hay 10 etiquetas de titulo duplicado. Y además en pinchado en cada uno de los títulos duplicados y me sale “La página que estabas buscando en este blog no existe”. Entonces, no entiendo porque me sale duplicada ¿qué tendría que hacer?
Cuando me meto en herramientas webmaster > Optamizacion > Mejoras HTML > Me sale en Etiquetas de título duplicadas, 10 páginas, y da la casualidad que todas las que aparece, no existe ninguna ¿qué puedo hacer? ¿Ese el problema, que ya aparecía en google y he desaparecido?
Hola Tere
Si ninguna de las páginas existe, no hay duplicidad. Puede haber sido un falla momentánea en el comportamiento del servidor o el CMS de tu sitio (si tiene uno), lo que provocó que el robot rastreara páginas falsas.
De todos modos debes quitarlas del índice desde Optimizacion >> Eliminacion de URL.
Salu2
Hola Fernando
Efectivamente, si quitas el bloqueo a las paginas bloqueadas, obviamente el buscador las vuelve a rastrear e ingresan nuevamente en el indice.
Salu2
Hola. Me gustaría saber si al quitar robots vuelves a recuperar
las paginas bloqueadas